2022年3月1日,国际计算机视觉与模式识别会议(IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022)官方公布论文收录结果,我院雷印杰教授团队在图像域泛化学习及点云域适应学习领域的研究被接收,包含Oral论文和Poster论文各一篇。CVPR是中国计算机学会A类推荐会议,在Google学术计算机科学领域中排名第1,所有领域出版物中排名第4。本届CVPR 会议有效投稿共8161篇,最终接收2067篇(接收率25.33%),其中口头报告论文(Oral)接受率约为5%。
雷印杰教授指导的三年级研究生彭铎以第一作者身份在该会议发表题为“Semantic-Aware Domain Generalized Segmentation”的论文,并受邀参加会议口头报告(Oral Presentation)。该论文提出了一种基于语义感知的归一化与白化方法,通过类别特征的中心级与分布级对齐,实现了特征的类内紧凑性与类间分离性,以此在保留特征鉴别力的同时提高了模型的领域泛化性能;同样,二年级研究生金钊以第一作者身份在该会议发表题为“Deformation and Correspondence Aware Unsupervised Synthetic-to-Real Scene Flow Estimation for Point Clouds”的文章,该论文对点云场景流估计中“合成-到-真实”无监督域适应学习问题进行了研究,并构建了一个全新合成点云场景流数据集,针对性地提出了形变与对应关系感知的域适应场景流估计方法。
论文1:Semantic-Aware Domain Generalized Segmentation
背景:现阶段针对语义分割的域泛化特征对齐算法大多是采用特征归一化、特征白化、或者两者结合的方式,以期实现模型的自适应域不变特征提取。特征归一化方法通常利用实例归一化(IN)来消除特征风格差异,IN通过将多种风格的特征将聚拢在特征空间的中心区域,以消除不同风格特征之间的差异,然而,如图1 (a)所示,该方法仅能实现特征的中心对齐,没有考虑到特征的联合分布,很多不同风格的局部特征仍然存在较大的空间距离;特征白化方法通常采用实例白化(IW)来统一不同风格特征的空间分布,然而,如图1 (b)所示,尽管IW可以使得不同的风格特征具有相同的分布形状,但是不同风格的特征之间仍然存在明显的距离,导致跨域分割效果不理想;两者结合类方法主张利用IN与IW分别实现特征的空间中心化与分布标准化,以此在空间位置和联合分布的层面同时约束特征,然而,该方法没有进一步考虑到特征的语义类别属性,如图1 (c)所示,在特征中心对齐与分布对齐后,不同类别的特征可能会错误地聚拢到一起,类别属性的错配会导致模型在具体分割时难以鉴别种类,从而生成边界模糊甚至错误的分割结果。
创新:针对以上三种特征对齐方法共同存在的特征语义级对齐缺失问题,本论文提出基于语义感知的特征对齐方法,实现语义特征中心化对齐和语义特征分布级对齐。如图1 (d)所示,本章方法包含两个特征对齐模块:语义感知归一化模块(Semantic-Aware Normalization,SAN)和语义感知白化模块(Semantic-Aware Whitening,SAW),对特征按照语义类别进行拆分,之后按照类别对特征独立进行归一化与白化,本方法在保证特征鉴别力的同时,实现了中心级、分布级、语义级的特征对齐,缓解了类别特征错配带来的语义冲突问题。

图1 现有特征对齐类方法与本章方法对特征分布的影响对比
方法:1. 语义感知归一化模块(Semantic-Aware Normalization,SAN)SAN在特征归一化操作中引入语义感知部分,使得模型能够自适应地感知特征类别,以实现不同类别的特征分离,对分离特征单独归一化可以获得类别间互不干扰的中心对齐。具体而言,批次的图片在经过特征提取器后,获得了批次特征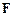 ,SAN的核心目标就是将特征拆解为类别特征,以实现类特征的实例归一化,当拥有语义分割的标签
,SAN的核心目标就是将特征拆解为类别特征,以实现类特征的实例归一化,当拥有语义分割的标签 时,可以很容易地得到类中心对齐特征,即目标特征
时,可以很容易地得到类中心对齐特征,即目标特征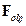 :
:
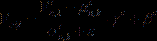 ,
,
其中,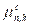 和
和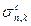 为批次内第
为批次内第 个特征,第
个特征,第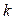 个通道的第
个通道的第 个类别的均值与标准差,
个类别的均值与标准差, 是随机初始化的微小值,与分母相加以防止除数为0,为每个类别设定了不同的仿射参数
是随机初始化的微小值,与分母相加以防止除数为0,为每个类别设定了不同的仿射参数 和
和 ,以此将不同类别的特征映射至不同空间位置,保持特征类与类间的距离。当拥有分割标签时,可以很轻松地定位到特征中某块区域的具体类别,然而,在真实应用场景下,用户不可能提前拥有语义分割的标签,因此,如何让SAN模块自身实现类特征的分离是本研究的关键。为此,本论文通过注意力机制来强化对应的类别特征,通过引入多支路的类别特征注意力机制,自然地实现类特征分离。
,以此将不同类别的特征映射至不同空间位置,保持特征类与类间的距离。当拥有分割标签时,可以很轻松地定位到特征中某块区域的具体类别,然而,在真实应用场景下,用户不可能提前拥有语义分割的标签,因此,如何让SAN模块自身实现类特征的分离是本研究的关键。为此,本论文通过注意力机制来强化对应的类别特征,通过引入多支路的类别特征注意力机制,自然地实现类特征分离。
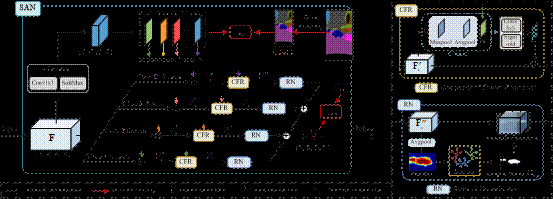
图2 语义感知归一化模块SAN结构流程图
具体过程如图2所示,SAN通过将语义分割的分类器所产生的输出特征进行拆解,获得了神经网络对每个类别区域的粗略判别结果,通过将其点乘于各类别支路上,获得了初步增强的类别特征 ;由于单从浅层特征的语义分割结果中很难获得精确的类别定位,因此本论文提出利用类级别特征优化模块CFR对以上初步增强的类别特征进行二次优化,以提炼获得更精准的类别特征
;由于单从浅层特征的语义分割结果中很难获得精确的类别定位,因此本论文提出利用类级别特征优化模块CFR对以上初步增强的类别特征进行二次优化,以提炼获得更精准的类别特征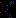 ;之后,将特征进行平均池化获得特征激活图,通过k-means聚类算法将具有较高激活值的区域挑选出来,以得到该类别的具体特征区域;最后,按照类别特征区域将所有分支的特征单独进行归一化,相加之后获得类别中心对齐的特征
;之后,将特征进行平均池化获得特征激活图,通过k-means聚类算法将具有较高激活值的区域挑选出来,以得到该类别的具体特征区域;最后,按照类别特征区域将所有分支的特征单独进行归一化,相加之后获得类别中心对齐的特征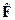 。
。
通过对语义分割输出的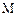 进行监督,使SAN具备有效的类别定位能力。同时,将输出的类别中心对齐特征与目标特征之间建立L1损失函数,确保模块获得可靠的类特征分离能力。
进行监督,使SAN具备有效的类别定位能力。同时,将输出的类别中心对齐特征与目标特征之间建立L1损失函数,确保模块获得可靠的类特征分离能力。
2. 语义感知白化模块(Semantic-Aware Whitening,SAW)SAW旨在对类中心对齐的特征实现进一步的语义分布级对齐。SAW通过充分挖掘通道和类别的相关性来判别通道的类别属性,从而将不同类别的通道放入同一分组进行去相关。具体而言,SAW依照模型分类器的权重,来寻找与各类别具有高度相关性的通道,将这些关联度高的类别通道集合到一个分组内,用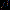 来表示,
来表示, 代表与第类有关的第
代表与第类有关的第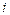 个高关联通道索引。由此,得到了SAW特征分组:
个高关联通道索引。由此,得到了SAW特征分组: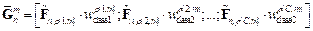 ,
,
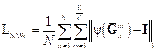 ,
,
其中,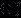 为SAW模块中第个样本的第
为SAW模块中第个样本的第 个特征分组,
个特征分组, 为对应的分类器权重。通过抹除组内不同类别通道的相关性,在保护特征结构信息的基础上,实现了语义特征的分布级对齐。
为对应的分类器权重。通过抹除组内不同类别通道的相关性,在保护特征结构信息的基础上,实现了语义特征的分布级对齐。
实验:(1) 表1展示了本论文所提方法与其他跨域分割方法的对比结果,Baseline特指在不加任何策略下,骨干神经网路的跨域分割性能,†代表复现的方法。以下展示部分实验结果,更多结果和分析详见原文。
表1 不同域泛化方法的跨域分割性能比较
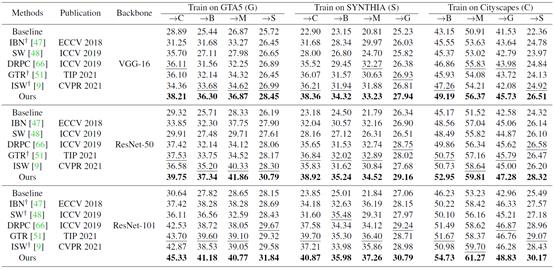
表2 SAN与SAW模块的消融实验结果

(2) 为了验证SAN与SAW模块的有效性,通过构建消融实验,分别在四种设定下开展跨域语义分割的测试工作,具体为:Baseline、模型仅用SAN、模型仅用SAW、两者兼用。由表2可知,与Baseline相比,SAN和SAW分别取得了8.71%和7.93%的显著平均增益,以此证明了SAN和SAW在跨域语义分割任务中具有明显效力,当两者兼用时,分割模型在4种跨域设定上都进一步提升了2个点的性能,以上证明了SAN和SAW的有效性与互补性。
(3) 如图3所示,可视化结果直观地展示了本论文所提方法的性能优势。
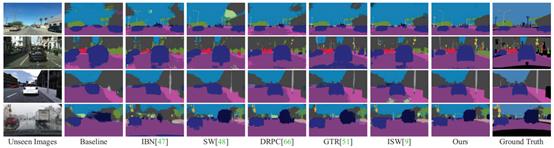
图3 不同域泛化方法的可视化语义分割结果对比
总结:在本文中,我们提出了两个模块来解决语义分割的领域泛化问题:语义感知归一化(SAN)和语义感知白化(SAW),它们依次执行语义特征的中心对齐和分布式对齐,以实现域不变特征的有效提取,详细的实验证明了SAN以及SAW的有效性。
论文2:Deformation and Correspondence Aware Unsupervised Synthetic-to-Real Scene Flow Estimation for Point Clouds
背景:场景流估计(Scene Flow Estimation)旨在从连续帧中预测三维运动场(3D Motion Field)。作为光流的一般化形式,场景流表示物体的三维运动并可用于预测物体将来运动,其在机器人导航和自动驾驶等领域有着重要应用价值。随着三维传感以及数据驱动技术的发展,基于深度学习的点云场景流估计方法引起了国内外学者的广泛关注。由于训练模型所需的逐点场景流标签的人工标注成本高,近年来,研究者们常常利用合成数据与直接生成的标签进行训练,从而避免人工标注过程。尽管这种利用合成数据训练并在真实数据上测试(即合成-到-真实)的方法取得了良好的效果,但其在实际应用中仍面临着以下几方面挑战。首先,现有用于场景流估计的合成数据集较为稀缺且与真实场景差异较大,目前还缺乏能够充分捕捉真实世界动态的合成数据,这增加了模型从合成到真实的迁移难度。其次,合成与真实数据间不可避免存在域间隙(Domain gap),这将造成直接迁移的模型出现性能退化。然而目前对于点云场景流估计任务,如何克服这种合成到真实域间隙以提升模型鲁棒性,仍是一个未被有效解决的问题。
创新:一方面,本文利用GTA-V游戏引擎构建了一个面向自动驾驶场景的大规模合成点云场景流数据集,以获得更加拟真的合成数据与标签,且无需人工干预。另一方面,本文提出了一种新的用于点云场景流估计的无监督域适应框架,采用教师-学生的学习范式为无标注真实点云数据提供自生成的伪标签,并显式地结合了形状变形正则(Deformation Regularization, DR)和表面对应优化(Correspondence Refinement, CR),以解决域迁移中的场景流畸变和偏离问题。
方法:在域适应方面,本文考虑无监督域适应(Unsupervised Domain Adaptation)的设定,即目标域标签不参与网络训练。模型框架如图4所示,主要包含学生模型和教师模型两部分,教师模型采用指数移动平均(Exponential Moving Average, EMA)的方式更新参数:

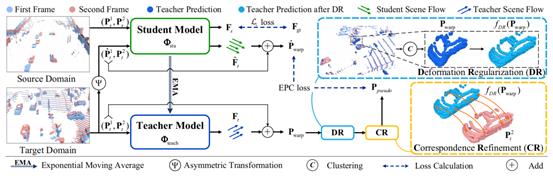
图4 本文所提出的无监督域适应模型框架
模型整体输入包含源域(合成数据)和目标域(真实数据),均为连续帧点云的形式。源域数据输入学生模型,并利用场景流标签计算L1损失。目标域数据输入教师模型,并同时经非对称变换对第一帧点云产生扰动后输入学生模型,通过约束学生模型的最终预测结果与教师模型一致,从而提高学生模型在目标域上对扰动的鲁棒性。
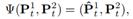
在其过程中,可以看作教师模型为学生模型提供伪标签(pseudo label),并通过约束二者预测场景流与第一帧点云相加的结果相同,达到终点一致性(End-Point Consistency, EPC)的目的。为提高模型面向目标域的表现性能,本文利用DR与CR进一步提升教师伪标签的质量。其中,DR的作用为物体形变校正器,首先加上场景流后的教师模型预测结果进行聚类,进而采用Kabsch算法对每一簇点云估计刚性运动的旋转与偏移参数,并通过刚性运动参数得到重建后点云:
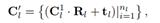
重建后点云将保持原始输入点云的刚体形状,从而有利于克服失准场景流导致的形变。
进而,通过CR模块提升教师模型预测场景流的精准度。CR在教师预测结果的基础上,利用拉普拉斯坐标进行点云表面几何描述:
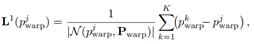
由于第二帧点云可以看作场景流估计的目标帧,即第一帧物体经过运动与第二帧对应物体表面重合,而场景流则是被用来描述这一运动过程。因此,进一步推广到帧间拉普拉斯坐标的计算:
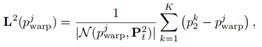
采用帧内与帧间坐标之差为重建后点云提供优化矢量,并最终得到经DR刚体运动重建与CR表面对应优化后的伪标签:

学生模型的总体损失函数包含源域损失函数与一致性损失函数两部分,其中源域损失函数为预测场景流与标签间的L1损失,一致性损失函数为:
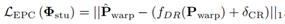
整个过程中,教师模型不断提供高质量的伪标签,以提高学生模型对真实数据的认知;学生模型的进步反过来通过EMA得到更好的教师模型,二者相互协同以克服域差异。
在数据集方面,本文利用GTA-V游戏引擎构建自动驾驶场景,随后在所驾驶车辆的车顶安装一个虚拟激光雷达收集器,以预定的频率(如10Hz)采集点云。为了标注场景流向量,本文遵循前人工作的刚性假设,计算每个实体的刚性运动。在游戏运行期间,每个单独的对象被分配一个唯一的实体ID,它被认为是一个刚体,通过如下方式计算逐点场景流:

对于下一帧中没有对应实体的点,本文以类似的方法计算其自我运动场景流,即所驾驶车辆运动所导致的周边物体相对移动。此外,由于属于地面的点对于场景流估计无实际意义,因而通常会被去除,本文通过游戏读取的实体信息对地面点进行去除。本文提出的GTA-SF是一个用于真实场景流估计的大规模合成数据集,它包含了54287对带有密集标注场景流的连续点云,更多分析与展示详见原文。

图5 本文所提出的GTA-SF数据集与现有合成与真实数据集对比
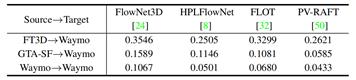
实验:(1) 本文首先测试了多种目前广泛使用的点云场景流估计模型,通过对比它们从不同源域直接迁移到目标域的性能,验证了:1)现有合成数据与真实数据间存在较大域间隙,导致模型出现性能退化;2)本文提出的GTA-SF数据集能够有效降低域间隙造成的模型性能退化。
表3 不同方法从源域到目标域的直接迁移性能比较
(2) 以HPLFlowNet作为基线模型,与现有域适应方法性能对比,所提出的方法在从两个合成数据集到三个真实数据集的6组迁移实验中,均表现出优异的性能,能平均缩小60%的EPE指标域间隙。
表4 域适应性能对比(基于HPLFlowNet)
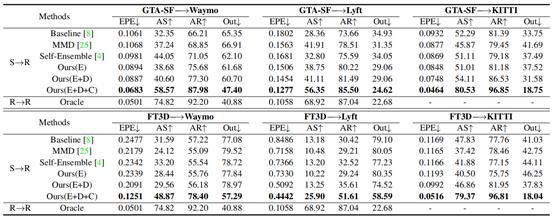
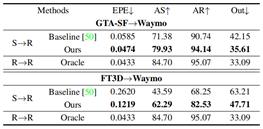
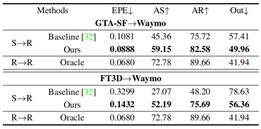
(3)分别以PV-RAFT和FLOT作为基线模型,验证本文所提出的域适应方法的通用性。
表5 基于PV-RAFT的域适应性能 表6 基于FLOT的域适应性能
(4) 图6可视化展示了本文所提出的方法对形状畸变与对应关系的优化效果。

图6 Waymo数据集上的域适应效果定性比较
总结:本文针对点云场景流估计中的合成-到-真实迁移学习所面临的问题,构建了一个大规模自动驾驶场景合成点云场景流数据集,其相比现有合成数据集具有更加拟真的特性,此外提出了一个新的域适应学习框架,通过在教师学生学习范式中显式地结合刚体形变正则与对应关系优化,提升模型的域适应能力。经过充分实验证明了本文所构建的合成数据集与提出的域适应框架均能有效提高模型的域适应性能。
文献:
D. Peng, Y. Lei*, M. Hayat, Y. Guo and W. Li. Semantic-Aware Domain Generalized Segmentation. in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. (Oral Presentation)
Z. Jin, Y. Lei*, N. Akhtar, H. Li and M. Hayat. Deformation and Correspondence Aware Unsupervised Synthetic-to-Real Scene Flow Estimation for Point Clouds. in: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022.
